Welcome to
Leumit Start introduces Pay & Research, the game-changer in EMR preliminary data access. Get started with your POC in just two working days with our revolutionary platform.
Obtaining access to medical data is a time-consuming and expensive process. Pay & Research changes everything about gaining access to EMR data!
Changing the Rules
of Engagement
Reduced Costs
Accessing medical data for research and development can be expensive.
Our innovative engagement model enables us to provide you with a significantly more affordable access to our comprehensive synthetic medical records for €2,500 + VAT.
Reduced Time
The process of signing a data sharing agreement might take months.
However, in Pay & Research, our uniform and simple agreement, streamlines the typically long legal procedures for such collaborations, accomplishing it within just two working days.
Reduced Bureaucracy
Signing collaboration agreement and obtaining IRB approval (Helsinki) consist of a lot of paper-work.
By signing a generic agreement digitally and using synthetic data, we reduced the bureaucracy to a minimum.
01
Register
Explore and review the Data Description section to ensure it contains the data you’re looking for. Then, click the Register button.
02
Sign & Pay
We will call you to schedule a video meeting to verify your identity. After that, you will need to sign the Terms of Use Agreement and complete the payment.
03
Get Access
You will receive guidance on connecting to the Virtual Lab Room, where you can proceed to install your analysis tools. Once the installation is complete, we will upload the synthetic dataset to your Lab Room, enabling you to begin your work.
About the
Data set
The data intended for sharing is a “one size fits all” synthetic data, based on real-world, raw data from Leumit’s EMR.
The synthetic data represents patients’ information from 2003 until June 2018 but due to the synthesis process the data will be spread beyond this range (for computational reasons only).
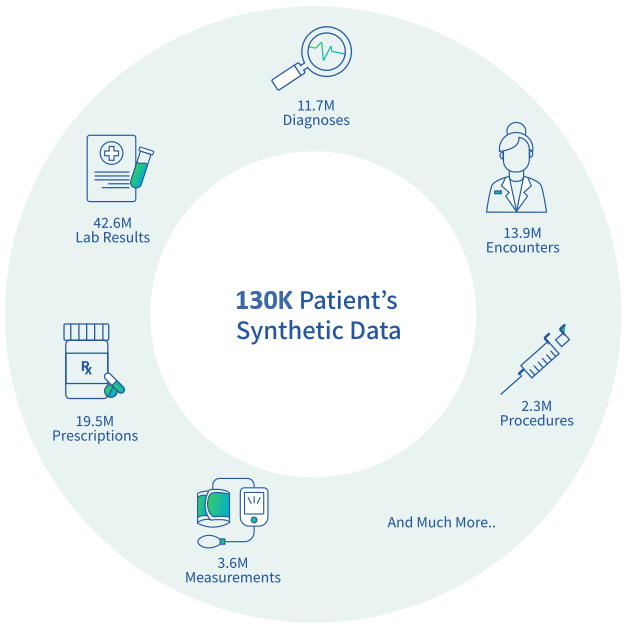
The data contains information on approximately 130,000 synthetic patients in a distribution close to reality in Leumit. The data however, does not claim to be a full representation of the population. For a more in-depth explanation, please refer to the attached file below.
This cohort is randomly selected and is a representative sample of the population in terms of demographic, medical condition and other aspects. The synthetic data is structured in such a way that it simulates the statistical behavior of the real population and enables a reliable analysis and a very close approximation to the real-world data.
The data will be accessible in CSV format files and contains the following types of information:
- Customer Details: Gender, demographics, customer status, etc.
- Provider’s Treatments: Data regarding hospitalizations, ERs, and other treatments (treatment code, date, etc.) as reported by external providers.
- Physician’s/Nurse’s Procedures: Procedures performed by the Physicians/ nurses in the HMO clinics (Procedure code, date, etc.).
- Medication Consumption: Data regarding medication consumption (Date, Drug ATC7 code, Quantity, etc.).
- Medication Prescriptions: Data regarding prescriptions for medications given by the Physician (Date, Drug ATC7 code, Dose, etc.).
- Physicians’ Details: License number (deidentified token), specialty.
- HMO Clinic Visits: Physician license (deidentified token), Customer token, date & time.
- Diagnosis – HMO: Diagnosis given by the HMO’s physicians encoded by ICD9 code (Physician license deidentified token), Customer token, date & time, ICD9, status, etc.).
- Diagnosis – Hospitals: Diagnosis given by the hospital’s physicians encoded by ICD9 code (Hospital, Date, ICD9) (data from 2007, gradually added).
- Medical Measures: Height, weight, heartbeat, blood pressure, etc.
- Sensitivities: Medications, allergies, food, etc. (Date, type, description, status, etc.).
- Laboratory Tests: Demands, Orders, Results (Date, type, name, Physician license (deidentified token), results, etc.).
- Medical Assessments: Data regarding estimations/ Assessments performed mainly by nurses (Date, assessment code, Nurse details, result, question & answer code, etc.
- Risk Factors: Such as smoking, drinking, drugs, etc. (risk code, date, value, etc.).
- Insurance Details: Insurance type, date start/end
In the table below, we have gathered data on the prevalence of a few common clinical conditions in the dataset that are often subjects of research (based on documented diagnoses). For detailed information on these conditions and the diagnoses that were included.
Diagnosis | Cohort size |
|---|---|
Colorectal cancer | 561 |
Lung cancer | 909 |
Breast cancer | 1075 |
Skin cancer | 2636 |
Diabetes | 10236 |
CKD | 2052 |
COPD | 3488 |
Asthma | 29258 |
Stroke | 1817 |
Dementia syndromes | 2146
|
NAFLD | 2784 |
Cardiovascular | 10092 |
Limitation in the dataset:
- The data does not contain any prices and costs.
- The data does not contain the names of locations (towns, cities etc.), providers and hospitals.
- Very rare occurrences are not fully reflected in the synthetic data.
- The synthetic data is not suitable for research related to seasonality.
- Medication names are based on the generic name and not the commercial name.
For more information about the synthetic data, please read carefully these two files:
MDClone – Leumit Synthetic Data solution
Leumit – The complete Data Catalog
Frequently Asked Questions
In order to accelerate research & development in data while keeping patient privacy, an innovative approach to data anonymization has developed in the past few years.
This approach is dealing with generating artificial patients’ records that reside on real patients’ data with high fidelity to real patients.
This approach is called Synthetic Data. Synthetic data is non-reversible, artificially created data that replicates the statistical characteristics and correlations of real-world, raw data. Utilizing both discrete and non-discrete variables of interest, synthetic data does not contain identifiable information because it uses a statistical approach to create a brand-new data set.
The reason we use Synthetic Data in Pay & Research is the ability to deliver data for research in days instead of months.
We use Mdclone’s technology to generate the Synthetic Data.
Following payment and signing the agreement you’ll get access to a Virtual Lab Room, where you’ll be able to upload and install any analysis tool you think you might need (Windows OS environment).
After confirming you have finished installing your research tools, we will take two steps:
1. We will disable Internet access in the Virtual Lab Room.
2. We will upload the synthetic data to the Virtual Lab Room.
After performing these two steps you’ll be able to log-in to the Virtual Lab Room and start your work on the Data.
Please notice that you should use tools that don’t need any on-line access to the Internet.
Virtual Lab Room is a concept in which the data research is done on a dedicated computer that the researcher connects to, and contains the Data itself and the research tools for the study.
In this way the data never leaves the organization, and the researcher can work from wherever he/she likes.
In our solution the Virtual Lab Rooms are hosted on Microsoft Azure machines running Windows OS environment.
You’ll connect to the machine using VPN.
Access to the Virtual Lab Room is configured for single-user access. However, access can be extended for an additional fee by prior arrangement with the support team.
After signing the agreement and purchasing the Pay & Research service, we’ll provide you access to the Virtual Lab Room in a few working days.
From that point you’ll have the ability to upload your analysis tools to the Virtual Lab Room.
When you confirm you finished installing the analysis tools, we’ll disconnect the Lab Room from the internet and upload the synthetic data set to the Lab Room.
This usually takes less than a few working days.
We’re here to assist you with any problem or concern.
You’ll need to contact our support team and we’ll get back to you shortly, and not more than one working day.
Your data is securely stored in your personal Virtual Lab room.
Only you and our support team can access this data.
In this case you’ll have to contact our support team and we’ll help you upload any tool or file you might need.
Please make sure to upload any tool you might need in advance.
Unfortunately, we can’t allow any raw data to be downloaded from the Virtual Lab Room.
You’ll be able of-course to download any analysis material and products based on the synthetic data you were working on (but not the raw data itself).
When you confirm you’ve finished your work, you’ll be asked to make sure that all relevant files are moved to a specific “export” folder, then we’ll organize your data to be downloaded without the raw synthetic data set.
The Virtual Lab Room operation will be paused after 30 days, unless you specifically ask to renew the subscription for another period of 30 days, at a cost of 2,000 NIS + VAT. We will inform you by email before the subscription period ends.
· The data contains information from 2003 to June 2018.
· The data does not contain any prices and costs.
· The data does not contain the names of locations (towns, cities etc.), providers and hospitals.
· Very rare occurrences are not fully reflected in the synthetic data.
· The synthetic data is not suitable for research related to seasonality.
· Medication names are based on the generic name and not the commercial name.
Read more about the data here.
Our platform runs on Microsoft’s Azure, and these are the specs of a standard Virtual Lab Room :
· Compute power: 4 cores CPU with 16 GB of RAM (VM size model in Azure: “Standard_D4s_v3”).
· Disk storage: 127 GB + dedicated 30GB storage for the RAW data.
· Operating System: Windows 11.
According to our experience, a standard Virtual Lab Room machine suits most cases regarding the analysis of structured data. However, by contacting us, you can upgrade to a more powerful machine with an additional payment, according to the costs in Azure, covering the difference from the standard machine.
Access to the Virtual Lab Room is configured for single-user access. However, access can be extended for an additional fee by prior arrangement with the support team.
You can contact us on the ‘Register‘ section or by email at innovation@leumit.co.il. Our office address and phone number are: Leumit Laatid, Harba 18/A, Tel-Aviv, P.C. 6473918, +972 (3) 6913775.
Unlock Instant Access to the Data You Need
Start your medical research journey today! Leave your name and email below to begin the process digitally. We’ll get back to you within two working days, answer your questions, proceed to signing the agreement, and complete the payment.

Pay & Research
Leumit Start is Leumit Health Services innovation and digital health unit. We aim to encourage Innovation in the HealthTech industry by supplying responsible and reasonable access to de-identified high quality clinical data, clinical consultancy, clinical trials and more. Leumit Start operates under Leumit La’atid Ltd.
Visit: www.innovation.leumit.co.il